On this page
- Can an AI agent fix vulnerabilities automatically?
- How does AI vulnerability auto-remediation work?
- Why most autofix is shallow
- Can you trust an AI-generated fix?
- What it does, and does not, do
- Which tools do AI auto-remediation?
- Frequently asked questions
- Can an AI agent find and fix vulnerabilities automatically?
- Can I trust an AI-generated security fix?
- Why can autofix make things worse?
- Does the agent open the pull request by itself?
- What kinds of vulnerabilities can AI auto-remediate well?
- How is this different from a SAST tool's built-in autofix?

The promise is seductive: an AI agent that reads your vulnerabilities, fixes them, and opens a pull request while you sleep. The reality is more useful than the promise once you understand where the agent is strong and where it needs help. An agent is excellent at applying a fix and weak at deciding what is a real, exploitable vulnerability, which is exactly the half a good scanner already solved. So the question is not "can AI fix vulnerabilities" but "what does the agent need around it to fix the right ones safely". This guide walks the find, fix, verify and open-a-PR loop, why most autofix is shallower than it looks, and whether you can trust the result.
Can an AI agent fix vulnerabilities automatically?
Yes, when it is given confirmed findings to act on rather than asked to discover them itself. The split matters: a coding agent is strong at rewriting a vulnerable line once it knows precisely what to change, and weak at the security-engineering judgment of whether an issue is real, reachable and worth fixing. That judgment is what a mature scanner already computed. So "automatic" means the scan finds and ranks, the agent fixes, and a human approves, not the agent improvising security from a blank prompt.
A bare agent asked to "fix the security issues in this repo" does something far weaker than it appears: it skims the open files, pattern-matches a few obvious smells, and misses everything your scanners spent real analysis finding. Give it the ranked findings, and the same agent becomes a fast, accurate remediation engine. The difference is entirely in what it is fed.
How does AI vulnerability auto-remediation work?
It works as a loop with four stages, and the agent only owns two of them. Detection and triage come from the platform; fixing and the PR come from the agent.
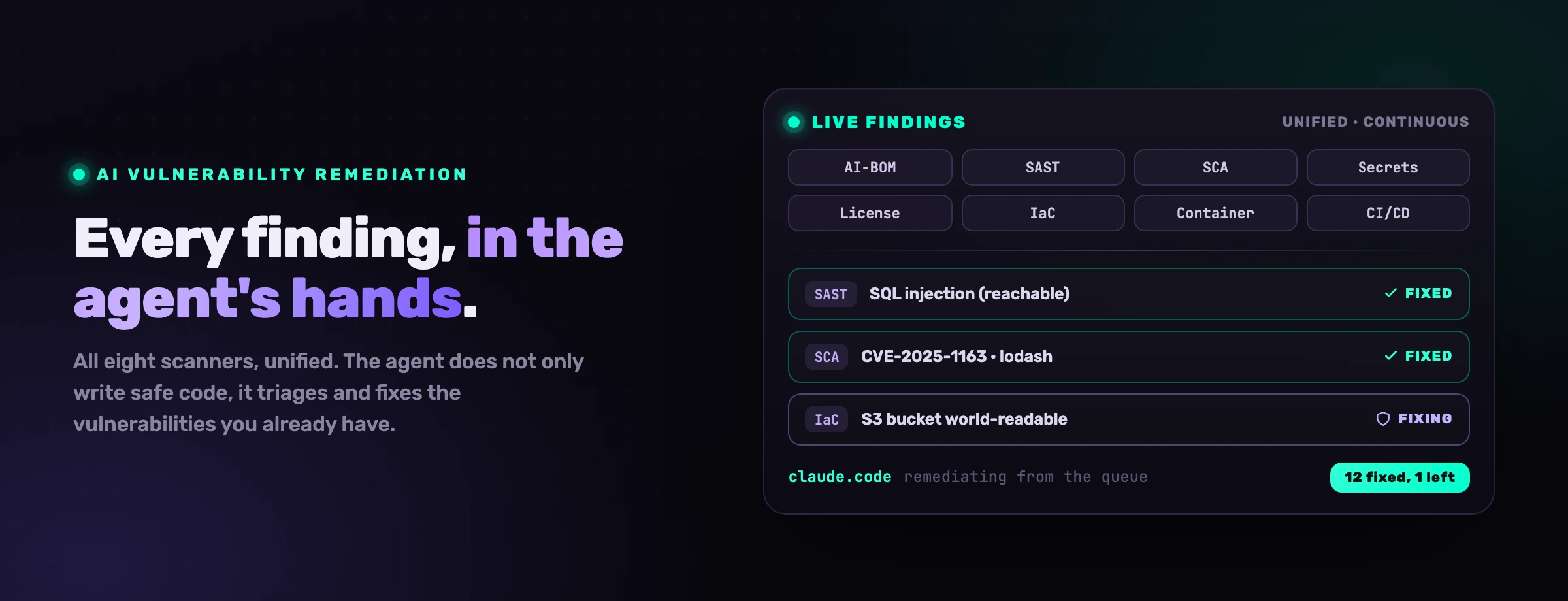
Find. Continuous scanning produces the raw findings: reachable injections, vulnerable dependencies, exposed secrets, misconfigured infrastructure. The wider and more unified this is, the better the next stages, because a fix made blind to the other findings is how you trade one vulnerability for another.
Triage. The findings are ranked by exploitability, reachability first, so the agent works the issues that can actually be reached and exploited rather than the thousand that cannot. This is the step that turns a backlog nobody touches into a short, ordered list.
Fix. The agent rewrites each site to fit your codebase, parameterizing the query, upgrading the dependency, scoping the query to the tenant, rotating the secret. Because it has the surrounding code and your conventions in context, the fix reads like your team wrote it, not a templated patch.
Verify and open a PR. The fix is checked (tests, a re-scan to confirm the finding closed) and lands as a pull request with the finding, the fix and the rule recorded, for a human to approve. Nothing merges on the agent's say-so.
Why most autofix is shallow
A lot of "AI autofix" is a single scanner suggesting a templated patch for one finding in isolation, with no knowledge of your business logic, your conventions, or the other findings around it. That is genuinely useful for a clear-cut injection, and risky everywhere else, because a fix that ignores context can create a new problem: a dependency bump that breaks a transitive constraint, an input filter that misses the deserialization path next to it, an authorization check added in one handler but not the three like it.
The deeper version is unified-context remediation: the agent fixes with every scanner's findings and your rules in view at once, so it does not patch a SAST issue while ignoring the SCA vulnerability underneath it or the secret two lines away. This is why the breadth of the platform feeding the agent matters as much as the agent itself, the argument we make in full in AI vulnerability remediation.
A fix that sees one finding can close one finding and open another. A fix that sees all of them, with your rules, closes the real one and leaves the rest intact.
Can you trust an AI-generated fix?
You can trust it the way you trust a capable contributor: review the diff, do not merge blind. The trust comes from the process, not the model's confidence. Three things make an AI fix trustworthy: it acts on a confirmed, reachable finding (not a guess), it is verified (a re-scan or test confirms the issue is actually closed and nothing obvious broke), and a human approves the pull request. Remove any of the three and you are back to hoping.
What you should not do is let the agent both decide and merge. The model is as confident about a wrong fix as a right one, so the human-in-the-loop on the PR is not bureaucracy, it is the control that makes speed safe. The right mental model is the agent as a high-throughput junior who drafts every fix and never merges their own work. We cover the broader "is AI code safe" question in is AI-generated code safe.
What it does, and does not, do
Be clear about the boundary so the value is real. Auto-remediation is excellent at the high-volume, well-defined classes: injection, vulnerable dependencies, exposed secrets, missing validation, common misconfigurations. It drains the backlog of reachable, known-pattern findings far faster than a human queue ever could.
It is not a substitute for design judgment. A business-logic flaw that needs a human to decide what the rule should be, an architectural change, a finding whose fix has product implications, those still need a person. The agent handles the volume so your engineers spend their judgment where judgment is needed, which is the whole point.
Which tools do AI auto-remediation?
The space is moving fast, and the tools differ mostly in what they see when they fix. A few reference points, fairly stated:
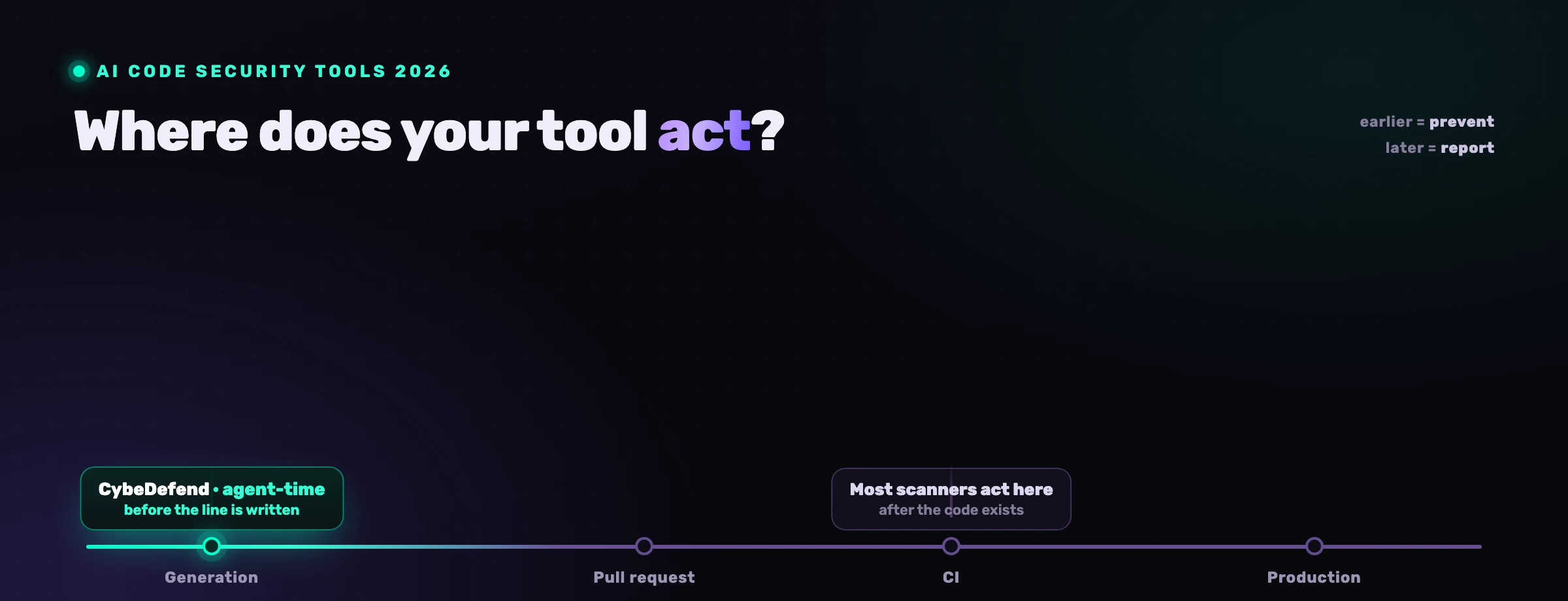
- Single-scanner autofix (for example Snyk's Agent Fix for its own findings, GitHub's Copilot Autofix for code-scanning alerts) is strong inside its own engine's view and patches one finding at a time. Great for the clear-cut cases in that engine's domain.
- Platform autofix from broader AppSec suites adds more finding types but often still fixes per-finding rather than with unified context.
- Agent-time, unified-context remediation (CybeDefend's approach) feeds every scanner's ranked findings plus your business and security rules into the coding agent you already use, so the fix is made with the full picture and lands as a reviewable PR.
The right choice depends on how much of your stack you want one fix to account for. The more unified the context, the safer the automatic fix. We lay out the full field in the best AI code security tools.
VibeDefend plus CybeDefend's platform is the unified-context version. The platform scans with eight engines and ranks by exploitability; VibeDefend, a free npm CLI, wires Claude Code, Cursor, Windsurf, OpenAI Codex and VS Code Copilot to those findings so the agent fixes the real ones in the loop.

The Live Findings layer is the one this article is about: it connects the agent to CybeDefend's full AppSec platform so every scanner result is live in the agent's context to triage and fix, while Business Rules and Security Rules keep the new code safe and the Action Guard blocks destructive calls. Nothing about your code crosses the wire; only structured governance metadata does, on EU or US tenants kept physically separate.
Frequently asked questions
Can an AI agent find and fix vulnerabilities automatically?
It can fix them and open a pull request automatically, but the finding and triage should come from scanners, not the agent's guess. A coding agent is strong at applying a fix once it knows exactly what to change and weak at judging whether an issue is real and reachable, which is what a mature scanner computes. Fed confirmed, ranked findings, the agent remediates the real ones at machine speed and lands each fix as a PR a human approves.
Can I trust an AI-generated security fix?
Trust the process, not the model's confidence. An AI fix is trustworthy when it acts on a confirmed, reachable finding, is verified by a re-scan or test that the issue is actually closed, and is approved by a human on the pull request. Never let the agent both decide and merge: it is as confident about a wrong fix as a right one, so the human-in-the-loop is what makes the speed safe.
Why can autofix make things worse?
Because a fix that sees only one finding can close it while opening another. Patching a SAST issue without seeing the SCA vulnerability underneath it, or adding an input filter that misses the deserialization path beside it, trades one problem for a new one. Unified-context remediation, fixing with every scanner's findings and your rules in view at once, avoids this, which is why the breadth of what feeds the agent matters as much as the agent.
Does the agent open the pull request by itself?
It can prepare and open the PR with the fix, the finding it closes and the rule that applied, but it does not merge. The PR is the review point: a human reads the diff, confirms the verification, and approves. This keeps the throughput of automation while keeping a person on the merge decision, which is the boundary that makes auto-remediation safe to run on a real codebase.
What kinds of vulnerabilities can AI auto-remediate well?
The high-volume, well-defined classes: injection, vulnerable dependencies, exposed secrets, missing input validation, and common infrastructure misconfigurations. These have clear, reachable signatures and contained fixes, so the agent clears them far faster than a human queue. Business-logic flaws and changes with design or product implications still need human judgment; the agent handles the volume so engineers spend their time there.
How is this different from a SAST tool's built-in autofix?
A scanner's built-in autofix patches one finding from one engine in isolation, with a templated change and no view of your business logic or the other findings. Agent-time, unified-context remediation runs in the coding agent that understands your whole repository, works the ranked findings from every scanner at once, fits the fix to your code, and lands a reviewable PR. The difference is context: the more the fix sees, the safer it is.